Deploy Hive
前置
Hive 的使用需要依赖MySQL, 这里使用了mariadb来作为MySQL, 它是兼容MySQL的.
镜像拉取
docker pull mariadb
运行实例
| 参数 | 值 | 说明 |
|---|---|---|
| –i | 创建交互式会话 | |
| -t | 创建伪终端 | |
| -d | 后台启动 | |
| --privileged=true | 使用特权模式启动, 以允许容器对宿主机的写入 | |
| --name | mariadb | 容器名字 |
| --network | misaka | 将数据库接入misaka网络 |
| --ip | 192.168.60.100 | 容器IP |
| -p | 3306:3306 | 端口映射 |
| -v | /d/Desktop/BD/resolv.conf:/etc/resolv.conf | 挂载目录使dns持久化 |
| -e | MARIADB_ROOT_PASSWORD=123456 | 设置数据库root用户密码 |
| -e | MARIADB_DATABASE=hive | 创建名为hive的数据库 |
| -e | MARIADB_USER=hive | 创建数据库用户hive |
| -e | MARIADB_PASSWORD=123456 | 指定123456为上述用户的密码 |
更多环境变量及参数移步至官方文档
docker run -i -t -d --privileged=true --name mariadb --network misaka --ip 192.168.60.100 -p 3306:3306 -v /d/Desktop/BD/resolv.conf:/etc/resolv.conf -e "MARIADB_ROOT_PASSWORD=123456" -e "MARIADB_DATABASE=hive" -e "MARIADB_USER=hive" -e "MARIADB_PASSWORD=123456" mariadb
用 -v /d/Desktop/BD/mariadb/data:/var/lib/mysql 来本地挂载数据卷会导致 schemea 出问题, 不建议使用这么用, 默认会使用 docker 的 volumes 来挂载 /var/lib/mysql
给hive用户数据库权限
Grant all privileges on hive.* to 'hive'@'192.168.60.100' identified by '123456';

Hive 安装
从官网下载, 可以查看不同Hadoop所支持的Hive
由于我hadoop是3.2.4的, 所以我用hive-3.1.3
下载hive
wget https://dlcdn.apache.org/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz
解压hive
-C path 解压到指定目录
tar -zxf apache-hive-3.1.3-bin.tar.gz -C /usr/local/
重命名hive目录
解压出来的hive一般是这样的: apache-hive-3.1.3-bin, 为了方便配置可以重命名下
mv /usr/local/apache-hive-3.1.3-bin /usr/local/hive-3.1.3
设置Hive属组
chown -R root /usr/local/hive-3.1.3
添加hive环境变量
echo 'export HIVE_HOME=/usr/local/hive-3.1.3' >> /etc/profile.d/hadoop.sh
echo 'export PATH=$PATH:$HIVE_HOME/bin' >> /etc/profile.d/hadoop.sh
刷新环境变量
source /etc/profile
MySQL驱动包安装
mysql-connector-java-5.1.48.tar.gz包的获取就不多说了, 同理hive
解压
将该驱动包 mysql-connector-java-5.1.48.tar.gz 解压, 将其中的 mysql-connector-java-5.1.48-bin.jar 到 $HIVE_HOME/lib 中去
tar -zxf mysql-connector-java-5.1.48.tar.gz
mv mysql-connector-java-5.1.48/mysql-connector-java-5.1.48-bin.jar $HIVE_HOME/lib
# 删除解压出来的目录
rm -rf mysql-connector-java-5.1.48
版本选择
可以在mvnrepository找到所有jdbc的下载
建议使用适配版本, 最新版未必适合
我在 hive-3.1.3 使用 mysql-connector-java-8.*.* 版本时会出现版本不兼容的情况, 最后还是用回上面的 mysql-connector-java-5.1.48 版本
配置文件
配置文件在 $HIVE_HOME/conf 下
进入该目录
cd $HIVE_HOME/conf
hive-env.sh
复制 hive-env.sh.template 为 hive-env.sh
cp hive-env.sh.template hive-env.sh
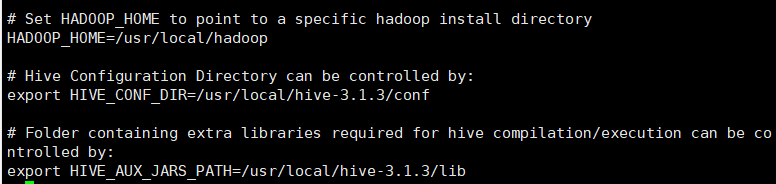
对 hive-env.sh 配置, 修改其 HADOOP_HOME, HIVE_CONF_DIR和 HIVE_AUX_JARS_PATH 三个配置项, 并将其注释去掉
HADOOP_HOME 是Hadoop的Home目录
HIVE_CONF_DIR 是Hive的配置目录, 默认为 $HIVE_HOME/conf
HIVE_AUX_JARS_PATH 是Hive存放jar包的路径 默认为 $HIVE_HOME/lib
hive-default.xml
从模板中复制一份, 该文件为Hive默认加载文件可不用修改
cp hive-default.xml.template hive-default.xml
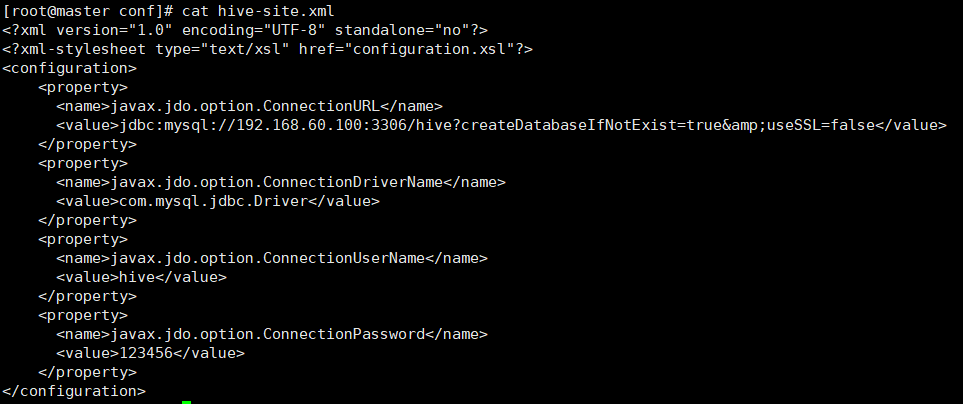
hive-site.xml
在 $HIVE_HOME/conf 中新建文件 hive-site.xml, 并向其中添加如下内容
192.168.60.100是 mariadb 的 IP
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.60.100:3306/hive?createDatabaseIfNotExist=true&useSSL=false&characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
</configuration>
Hive 运行
初始化hive
这是将hive的数据库操作类型设置为mysql, --verbose 参数可以获得更加完整的日志信息, 方便追踪错误
schematool -initSchema --verbose -dbType mysql

初始化问题
包括但不限于: JDBC版本不兼容, Hadoop与Hive版本不兼容, hive数据库已存在 等
启动Hadoop集群
提示
运行hive前一定要先启动Hadoop集群否则会出错
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver
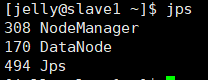
查看Hadoop服务进程
jps
主节点

从节点
进入hive
hive
查看下数据库, 或者使用其他的mysql命令来测试hive的可用性
show databases;
CLI乱码处理
如果在hive的CLI中输入中文变成一串问号, 需要在 $HIVE_HOME/conf/hive-env.sh 文件的最后加上编码格式
export HADOOP_OPTS="$HADOOP_OPTS -Dfile.encoding=UTF-8"
然后再重启hive
hive restart
汽车销售数据分析系统实战
相关文件
| 文件 | 说明 |
|---|---|
| create_cars.sql | 创建cars数据库和数据表 |
| cars.txt | 待写入数据文件 |
创建cars数据库表
在hive中执行下述命令以建立cars数据库, source 后跟主机路径, 而非 hdfs 内的路径
source create_cars.sql;
查看数据库表并退出
use car;
show tables;
exit;
提示
hadoop fs 与 hdfs dfs 等价
上传数据到hdfs中
上传前先检查下hdfs中是否存在 /cars 目录
hdfs dfs -ls /
没有就先创建
hdfs dfs -mkdir /cars
如果 /cars 目录内存在 cars.txt 文件, 再次上传前需要先删除该文件
hdfs dfs -rm /cars/cars.txt
上传 cars.txt 到 hdfs 中的 /cars 目录内
hdfs dfs -put cars.txt /cars
验证是否上传成功
hdfs dfs -ls /cars

将数据对数据库进行外联接
use car;
load data inpath '/cars/cars.txt' into table car_2019712;

查看hive仓库的内容
select * from car.car_2019712 limit 10;

统计乘用车辆和商用车辆的销售数量和销售占比
①统计乘用车辆和商用车辆的销售数量
根据使用性质字段 nature 进行分组统计乘用车和商用车的总数量, 乘用车辆的使用性质为非营运, 商用车辆的使用性质为营运
select '非营运', sum(if(a.nature='非营运', a.cnt, 0)), '营运',
sum(if(a.nature!='非营运', a.cnt, 0))
from (select nature,count(*) as cnt from car_2019712
group by nature having nature is not null and nature != '') a;

②统计汽车销售总数量
select count(*) from car.car_2019712;

③计算销售占比
乘用车辆的销售数量占比 = 66478/70640 ≈ 94.1%
商用车辆的销售量占比 = 3884/70640 ≈ 5.5%
统计山西省2013年每个月的汽车销售数量的比例
分别统计出山西省2013年每个月的汽车销售数量和山西省2013年年度汽车销售总数量, 再用2013年每个月的汽车销售数量除以年度销售总数量
select month, c1.ss/c2.sumshu from
(select month,sum(quantity) as ss from car.car_2019712
where province='山西省' and year='2013' group by month) c1,
(select sum(quantity) as sumshu from car.car_2019712
where province='山西省' and year='2013') c2;

根据计算结果可知, 汽车销售销售的高峰期位于10月到1月, 这四个月的汽车销售数量都占到全年销售的10%, 其中一月份最为显著, 达到了14.8%
注意
若代码报错如下报错,则分别运行一下两行命令以解除禁用
FAILED: SemanticException Cartesian products are disabled for safety reasons. If you know what you are doing, please sethive.strict.checks.cartesian.product to false and that hive.mapred.mode is not set to 'strict' to proceed. Note that if you may get errors or incorrect results if you make a mistake while using some of the unsafe features.
set hive.strict.checks.cartesian.product=flase;
set hive.mapred.mode=nonstrict;
统计买车的男女比例及男女对车的品牌的选择
①统计买车的男女比例
select '男性', a.nan*1.0/(a.nan+a.nv),'女性 ', a.nv*1.0/(a.nan+a.nv) from
(select '男性',sum(if(b.gender='男性',b.cnt,0))as nan,
'女性',sum(if(b.gender='女性',b.cnt,0))as nv from(
select gender,count(*) as cnt
from car.car_2019712 group by gender having gender is not null and gender!='') b)a;

根据计算结果, 男性占比70.1%, 女性占比29.9%
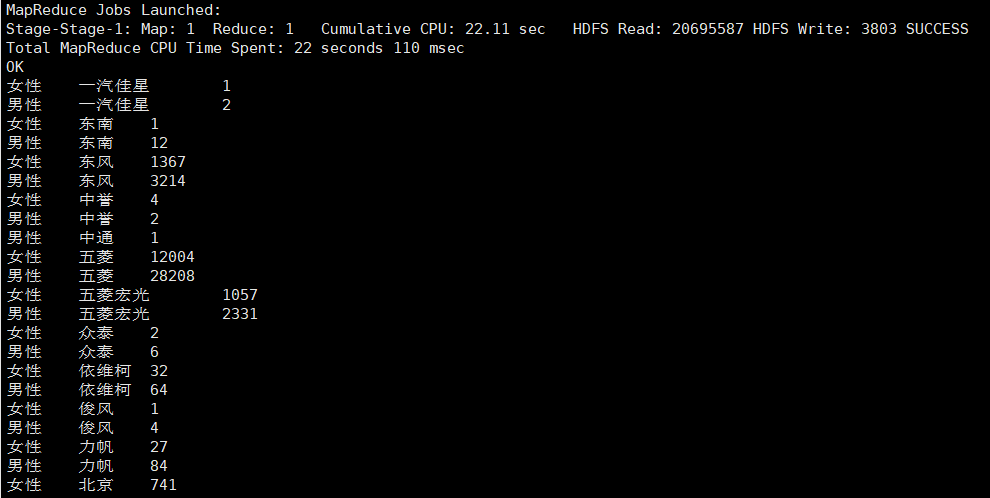
②统计男女对车的品牌选择比例
select gender,brand,count(*) from car.car_2019712
where gender is not null and gender!='' and age is not null
group by gender,brand having brand is not null and brand!='';
统计车的所有权、车辆型号和车辆类型
①统计车的所有权
根据车辆的所有权字段 owership 进行分组统计, 得出属于个人的车辆总数, 属于单位的车辆总数或者其他
select ownership, count(*) as cnt from car.car_2019712
group by ownership order by cnt desc;

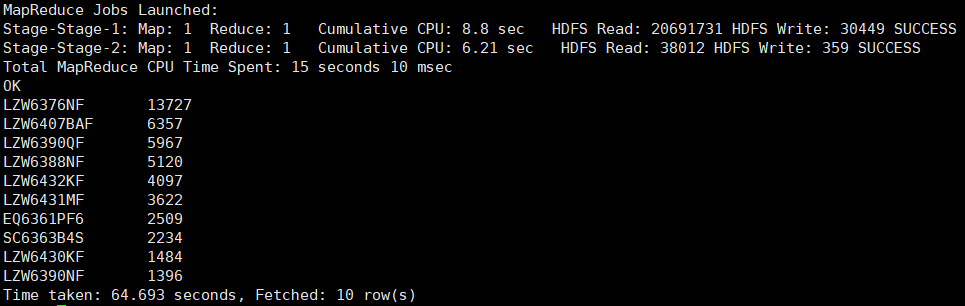
②统计车辆型号
根据车辆型号字段 model 进行分组统计, 得出各种不同车辆型号的总数量
select model, count(*) as cnt from car.car_2019712
group by model order by cnt desc limit 10;
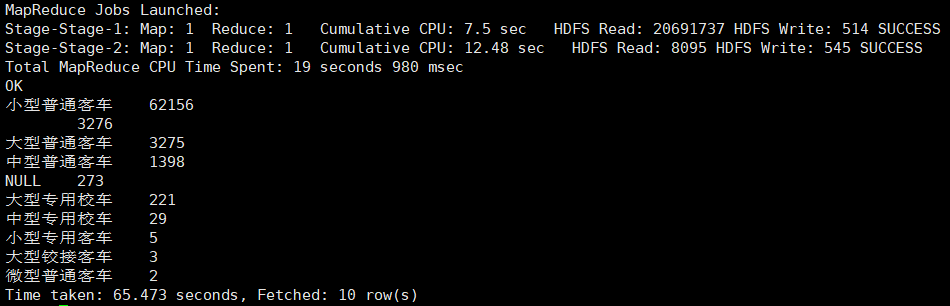
③统计车辆类型
根据车辆类型字段vehicletype进行分组统计
select vehicletype, count(*) as cnt from car.car_2019712
group by vehicletype order by cnt desc limit 10;
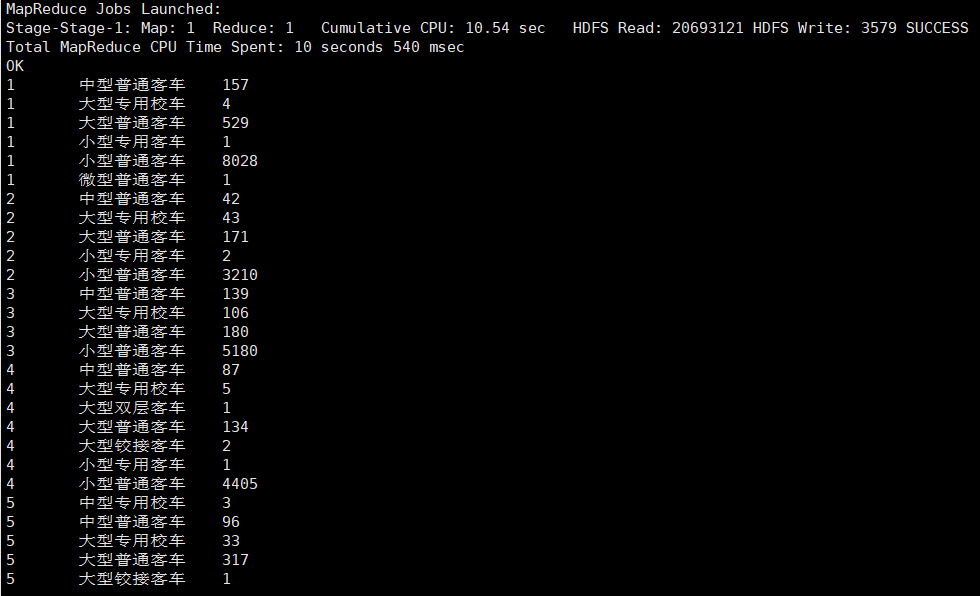
统计不同类型车在一个月的总销售量
统计不同类型车在一个月的总销售量, 即统计某一年某一个月某一类型的车
select month, vehicletype, count(*) from car.car_2019712
group by vehicletype, month having month is not null
and vehicletype is not null and vehicletype !='';
通过不同类型(品牌)车销量情况,来统计发动机型号和燃料种类
根据车辆的品牌字段 brand, 发动机型号字段 enginemodel 和燃油种类字段 fuel 进行分组统计
select brand, enginemodel, fuel, count(*) from car.car_2019712
group by brand, enginemodel, fuel;
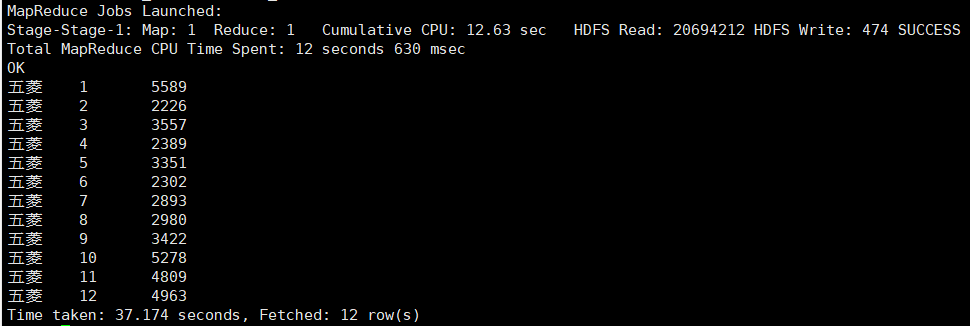
统计五菱某一年每月的销售量
根据汽车的品牌 brand 和月 month 两个字段进行分组统计, 并从结果中将品牌名为 五菱 的数据过滤出来
select brand, month, count(*) from car.car_2019712
group by brand, month having brand='五菱';